 |
|
BUENAS PRÁCTICAS EN J2EE. SEGUNDA PARTE. VERSION
PARA IMPRIMIR Informe de Traducido
y abreviado con permiso por 5. DESPLIEGUE El despliegue es una de las etapas finales del desarrollo de software. En ella, se copian todos los archivos que se necesitan para ejecutar una aplicación del entorno de desarrollo al de producción. El resultado de la etapa de despliegue es una aplicación ejecutable ubicada en un entorno de producción. 5.1. Buena práctica número 12. Siga la especificación estándar J2EE para empaquetado La especificación J2EE describe los artefactos necesarios para el proceso de despliegue y su ubicación en el servidor, permitiendo así la portabilidad de las aplicaciones y sus componentes. A continuación, se muestra una lista de módulos que incluye la especificación:
Los descriptores de despliegue son archivos de configuración XML que contienen toda la información necesaria para desplegar los componentes de un módulo así como las instrucciones para combinar los diversos componentes dentro de una aplicación. Dada la complejidad del empaquetado, se debería aplicar una herramienta de verificación J2EE, como la que proporciona el SDK J2EE, sobre el archivo EAR resultante antes del despliegue. Una herramienta de verificación comprueba que el contenido del despliegue esté bien formado y que sea consistente con las especificaciones de EJB, servlets y J2EE. 5.2. Buena práctica número 13. Utilice herramientas que ayuden en el despliegue A pesar de la excelente documentación que explica el proceso de despliegue, éste puede llegar a ser agotador, complejo y difícil de depurar. Afortunadamente, hay una variedad de herramientas que lo facilitan. Aunque la mayoría de entornos de desarrollo (IDEs) proporcionan un soporte adecuado para el despliegue, no se debería depender de estas tecnologías propietarias. Por el contrario, es preferible crear un guión que permita el despliegue sobre cualquier plataforma, aunque ésta no soporte el IDE. Para ello, Ant es la herramienta usada por la mayoría de los mejores programadores, ya que ofrece una serie de ventajas para desplegar aplicaciones J2EE. Usando Ant, se pueden desplegar aplicaciones de forma tan sencilla como ejecutar un comando. Ant tiene tareas incorporadas para crear archivos JAR, WAR y EAR. Además, puede automatizar también la copia de los archivos a su ubicación correcta en el servidor J2EE. La diferencia más importante entre un IDE y un guión (como los de Ant) para despliegues de gran tamaño es que el último se puede repetir fácilmente. Además, como un guión no requiere intervención manual, es una opción mucho más sólida para desplegar en un entorno de producción. 5.3. Buena práctica número 14. Respalde sus datos y su entorno de producción Debería tener precaución extrema cuando trabaje con máquinas de producción. Hay pocas cosas que causen un daño mayor que hacer cambios a un entorno de producción. Se puede evitar mucho sufrimiento si se hacen copias de respaldo. Planifique respaldar sus entornos de producción y de desarrollo. Es fácil de hacer y es lo que se debe hacer. Asegúrese de que sus copias de respaldo incluyan
archivos de aplicación, de configuración y
de datos. Respalde con regularidad y
también antes de cada despliegue. Así, en caso
de problemas, podrá recuperar fácilmente el último
estado bueno. 6. AFINACIÓN (TUNING) Quizás la etapa más descuidada en la mayoría de los proyectos de desarrollo es la de afinación. Esto es sorprendente, pues una de las causas más comunes de fracaso en grandes proyectos de software es un pobre rendimiento. Aunque muchos programadores llevan a cabo algo de afinación no estructurada, muy pocos construyen y ejecutan un plan de rendimiento que funcione. Aunque parte del problema se debe a la falta de buenas herramientas de afinación, esta situación está cambiando. Algunos vendedores están comenzando a incluir buenos servicios de perfilado en Java así como ayudas para la resolución de problemas. 6.1. Buena práctica número 15. Construya un plan de rendimiento Es necesario comenzar con un plan sólido de rendimiento. A continuación se detallan los componentes clave de dicho plan:
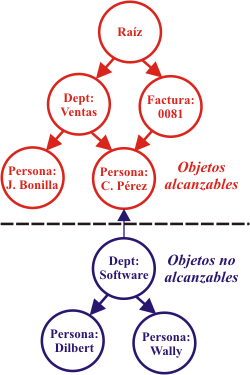
Después de que se ha construido el plan de rendimiento, éste debe ser aprobado por los interesados, se debe asegurar que se contará con los recursos y se debe ejecutar el plan. Normalmente las metodologías iterativas incluyen etapas que enfatizan el diseño de una solución, su construcción, pruebas y despliegue. Un análisis de rendimiento sólido se extiende por todas estas etapas. Resumiendo, los problemas tardíos de rendimiento han hecho fracasar muchos proyectos, pero si se cuenta con un plan sólido, se tendrá más probabilidades de salir ileso. La planificación de rendimiento es costosa pero las alternativas pueden ser catastróficas. 6.2. Buena práctica número 16. Gestione las fugas de memoria En este documento, una fuga de memoria (“memory leak”) es aquella memoria que la aplicación ya no necesita, pero que el recolector de basura (“garbage collector”) no libera. En sentido estricto, esto no es realmente una fuga: es simplemente que el programador no da la información suficiente al recolector de basura para que haga su trabajo. La recolección de basura en Java funciona identificando objetos que son alcanzables por la máquina virtual de Java, como se muestra en la figura 2. De forma periódica (por ejemplo, cuando la cantidad usada de memoria sobrepasa un cierto límite), la máquina virtual invoca al recolector de basura (GC). En la ejecución del programa, algunos objetos referencian a otros, creando un grafo dirigido. El recolector de basura examina todos los objetos en memoria y ve si son alcanzables desde el objeto raíz, es decir, si hay un camino en el grafo desde ese objeto raíz a cada objeto. Con esta información, el recolector de basura marca los objetos como alcanzables o no y libera todos los objetos que no son alcanzables.
Figura 2. El recolector de basura de Java funciona determinando los objetos que son alcanzables. Una flecha indica una referencia de un objeto a otro. Consecuentemente, si se ha dejado una referencia a un objeto en algún lugar, el objeto no puede ser liberado, pues puede ser alcanzado de alguna forma. Las fugas de memoria pueden ocurrir de muchas formas diferentes, pero sus causas son solamente unas pocas:
La mayoría de fugas de memoria en Java están comprendidas en una de las tres categorías anteriores. Estudiemos algunos casos especiales de fugas:
Estas son las fugas típicas. Seguramente, usted encontrará otras. Como las fugas de memoria son muy difíciles de encontrar, vale la pena comprender los patrones asociados con las mismas y aplicar a esas áreas un mayor escrutinio. Cuando se descubra una fuga, se debería usar una plataforma que ayude a identificarla. Resolución de fugas Para resolver los problemas de memoria, se deberían seguir los siguientes pasos:
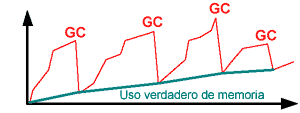
Figura 3. El eje vertical representa el uso de memoria y el horizontal, el tiempo. El aumento en los valles entre recolecciones de basura (GC) indica una fuga. 6.3. Buena práctica número 17. Concéntrese en las prioridades Una forma de la regla 80/20 dice que, típicamente, 80% de la ejecución de un programa ocurrirá en un 20% del código. Por ello, es importante concentrar los recursos de desarrollo en las áreas que probablemente tengan un mayor impacto sobre el rendimiento. Para ello, debemos considerar:
La clave de una afinación efectiva es una asignación
eficiente de recursos. Es decir, se debería invertir
la mayor parte del tiempo en afinar las áreas de la
aplicación que producirán el mayor beneficio.
Lo contrario también es cierto: no se debería
invertir tiempo intentando optimizar cada elemento de código
que se escribe, excepto si se sabe que es crítico
para el rendimiento. Esto no quiere decir que se deba escribir
código descuidado, sino que debe usarse el código
más simple que funcione, como mínimo hasta
que las pruebas manuales o automáticas de rendimiento
confirmen que es necesario optimizarlo. 7. ENTORNOS Aunque este documento de buenas prácticas se concentra en el desarrollo de software, en este apartado se estudiarán buenas prácticas para los entornos de desarrollo y producción. 7.1. Buena práctica número 18. Elija adecuadamente su entorno de producción Para despliegues de gran tamaño, se necesita diseñar el entorno de producción tan cuidadosamente como la aplicación. Las alternativas de despliegue que tienen mayor impacto sobre el desarrollo de la aplicación son los siguientes:
Capas de una aplicación Las capas ayudan a organizar la lógica de la aplicación. Pueden facilitar el mantenimiento, aumentar la flexibilidad y resolver problemas de despliegue. El catálogo de patrones J2EE reconoce de tres a cinco capas, dependiendo de los requerimientos de cada aplicación:
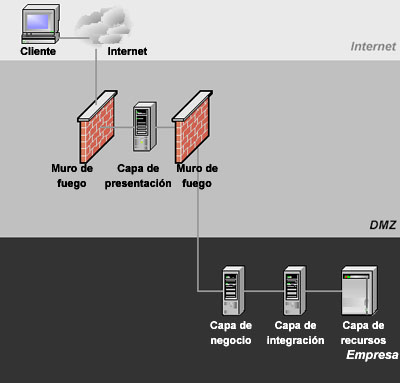
Diferentes configuraciones de despliegue La figura 4 nuestra una configuración común de despliegue, en la que se incluyen dos muros de fuego (“firewalls”) para aumentar la seguridad. La zona entre los dos muros de fuego (llamada la zona desmilitarizada o DMZ) contiene sistemas que necesitan una seguridad moderada y buen tiempo de acceso. Como los clientes externos deben atravesar el muro de fuego para llegar a la capa de presentación, los modelos que usan HTTP son la mejor opción para esta configuración.
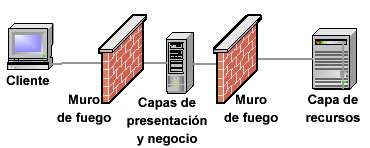
Figura 4. Diseño con cinco capas. Usualmente se utilizan dos muros de fuego. Aún así, es importante remarcar que se debería adaptar el entorno a los requerimientos de cada aplicación. Las arquitecturas complejas pueden escalar bien y ofrecer buena disponibilidad, pero estos beneficios tienen un costo. Por otra parte, algunos despliegues no necesitan capa de integración y otros pueden desplegar las capas de presentación y de negocio en una única máquina. Por ello, se puede optar por un entorno sencillo, como el que muestra la figura 5, que produce una configuración fácil de manejar y sorprendentemente robusta. Con el lenguaje Java y mainframes que son compatibles con Unix, se puede obtener un rendimiento sorprendentemente bueno con esta configuración. La ventaja de esta opción es que el sistema resulta más sencillo de diseñar y desplegar. Su inconveniente es que la lógica de negocio no está protegida detrás de un segundo muro de fuego.
Figura 5. Este despliegue incluye un servidor que contiene conjuntamente las capas de presentación y de negocio. Este servidor está dentro del muro de fuego externo pero fuera del muro de fuego interno. Cuando se requiere alta disponibilidad y un entorno más escalable, se puede usar clustering. Es importante elegir una plataforma que soporte clustering en cada una de las capas más importantes. Además, necesita elegir entre clustering horizontal o vertical. Estas son las opciones con las que cuenta:
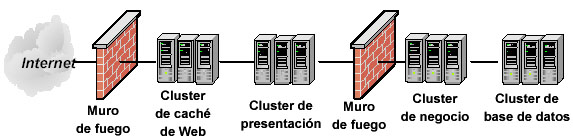
Considere el escenario en la figura 6. Este escenario despliega cuatro capas, con las capas de presentación, negocios y recursos implementando clustering. Además, se coloca el contenido Web estático en una caché, lo que ahorra comunicaciones costosas y puede mejorar dramáticamente el rendimiento. Una ventaja de este diseño es que no tiene un único punto de fallo, siempre que la implementación proporcione hardware de red redundante.
Figura 6. En un despliegue con clustering se obtiene escalabilidad añadiendo hardware y se aumenta la disponibilidad añadiendo redundancia. Por supuesto, conforme el entorno se hace más complejo, también se aumenta la complejidad de su administración. Conforme se añaden clusters y capas, se debe trabajar duro para que la administración del sistema global siga siendo sencilla. 7.2. Buena práctica número 19. No restrinja sus opciones de despliegue en tiempo de diseño Cuando sea posible, debería mantener la máxima flexibilidad mientras se construye el sistema. De esta manera, si necesita cambios en el despliegue, estará preparado para adaptarse a ellos. Esto requiere prestar una gran atención al diseño de la aplicación, de lo que nos ocuparemos a continuación. Gestión del estado de sesión Se puede usar una amplia variedad de técnicas para manejar el estado de sesión en aplicaciones Java del lado del servidor. Con independencia de la que use, debería asegurarse de que soporta estado distribuido de sesión.
Cada una de estas soluciones puede implementarse de forma que mantenga adecuadamente un estado distribuido de sesión. Caché Cualquier solución de caché que desarrolle para la aplicación debe soportar también acceso distribuido. Por esta razón, es mejor usar patrones de diseño y software preexistente para la mayoría de necesidades de caché. Además, tenga presente que el clustering puede degradar el rendimiento de la caché por dos razones:
Muros de fuego Asegúrese que entiende donde va a ubicar cada capa de la solución en relación a los muros de fuego. Cuando sea posible, use soluciones que no limiten sus opciones de despliegue. Por ejemplo, el cliente debería comunicarse con el servidor de presentación estrictamente usando HTTP o HTTPS. Incluso los clientes pesados o los applets de Java pueden usar estos protocolos si se programa con un poco de cuidado. 7.3. Buena práctica número 20. Cree un entorno de desarrollo que responda De todos los componentes que se necesitan para desarrollar software altamente complejo, ninguno contribuye más a la productividad del programador y a la calidad del código resultante que el entorno de desarrollo. El tiempo invertido en crear este entorno normalmente se recupera multiplicado por muchas veces en el transcurso del proyecto de desarrollo. Debería considerar los siguientes temas:
Como con todas las buenas prácticas, considere las
que funcionan para usted y descarte el resto. Estas sugerencias
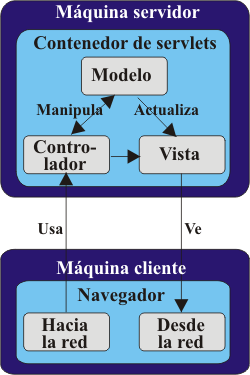
pueden mejorar dramáticamente su experiencia de desarrollo. 8. OTROS. 8.1. Buena práctica número 21. Utilice un framework MVC comprobado El patrón MVC es un patrón de diseño de vital importancia. MVC está compuesto de tres módulos diferentes, llamados Modelo, Vista y Controlador (de ahí su nombre). El Modelo está compuesto por el estado y los datos que la aplicación representa. La Vista es la interfaz de usuario que muestra información sobre el modelo y que representa el dispositivo de entrada que se usa para modificarlo. Finalmente, el Controlador es lo que une a los dos anteriores. Hace corresponder las peticiones que llegan del cliente con las acciones correspondientes y dirige las respuestas a las vistas adecuadas. Estas funciones de los componentes MVC pueden verse en la figura 7.
Figura 7. Interacción con el patrón MVC y dentro de él. Puede conseguir algunos resultados espectaculares sin más que separar la arquitectura de la aplicación entre los tres componentes MVC. Algunos de los beneficios del patrón MVC son:
Para implementar un framework MVC, hay una serie de opciones.
Puede implementar uno propio o puede aprovecharse de una
solución preexistente de código abierto o de
un vendedor específico, permitiendo una implementación
más rápida y una solución MVC más
robusta y mantenible. Compruebe la calidad de nuestro desarrollo offshore. Cursos de Aurum Solutions relacionados con el tema de este
artículo:
|
| |
|
|
|
|
|