|
Resolución
de fugas
Para
resolver los problemas de memoria, se deberían seguir los
siguientes pasos:
-
Reproducir
el problema. El primer paso (y el más
importante) es crear un caso de prueba que reproduzca
el problema. Para ello, puede comenzarse activando
la recolección de basura después
de ejecutar los casos de prueba. Cuando se examine
el uso total de memoria respecto al tiempo, se
formará un gráfico con picos y valles.
Los picos ocurren antes de que el sistema active
la recolección de basura. Los valles aparecen
después de la recolección de basura
y representan el uso verdadero de memoria en el
sistema. Si los mínimos en los valles aumentan
a un ritmo constante, como en la figura 3, se ha
encontrado una fuga de memoria.
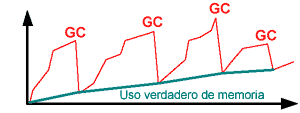
Figura
3. El eje vertical representa el uso de memoria y
el horizontal, el tiempo. El aumento en los valles
entre recolecciones de basura (GC) indica una fuga.
-
Aislar
el problema. Después de reproducir
el problema, se debe intentar aislar el problema
acotando el caso de prueba. Con frecuencia, se
encuentra la fuga de esta forma, sin necesidad
de más investigación.
-
Encontrar
los objetos que molestan. El siguiente
paso es usar un perfilador de memoria para localizar
los objetos en memoria en los que se encuentra
la fuga. Así, se comienza identificando
bloques de memoria anormalmente grandes. Entonces,
se comprueba el número de instancias de
estos bloques y, a continuación, se activa
la recolección de basura para los mismos,
volviendo a contar el número de instancias
de nuevo. Así se puede determinar si el
sistema está liberando los objetos como
debería.
-
Encontrar
y reparar referencias a esos objetos. Cuando
se ha identificado el objeto causante de la fuga,
se pueden encontrar referencias al mismo y repararlas,
lo que implica asignarlas a null o bien
realizar otros pasos de limpieza (cerrar un archivo,
eliminar una referencia de una colección,
etc.). La limpieza debería realizarse en
un bloque finally y no en el cuerpo principal
de un método, para asegurarse de que se
ejecuta incluso cuando las excepciones interrumpen
la ejecución del programa.
-
Prevenir
futuros casos del problema. Cuando sea
posible, se deberían eliminar las causas
de los problemas que causaron las fugas para evitar
que se repitan en el futuro.
6.3.
Buena práctica número 17. Concéntrese en las
prioridades
Una
forma de la regla 80/20 dice que, típicamente, 80% de la ejecución
de un programa ocurrirá en un 20% del código. Por ello,
es importante concentrar los recursos de desarrollo en las áreas
que probablemente tengan un mayor impacto sobre el rendimiento. Para
ello, debemos considerar:
-
El
análisis de puntos calientes (Hot
spot analysis) determina las secciones de código
más activas para que los programadores concentren
en ellas sus esfuerzos de optimización.
-
Las
medidas de rendimiento pueden localizar
casos de prueba que son críticamente lentos
de forma que pueda variar la ejecución para
que pase por las secciones de código con
mayor importancia en el rendimiento, con el fin
de poderlo optimizar.
-
La
automatización de las pruebas de rendimiento permite
establecer criterios sólidos de rendimiento
para los casos de prueba y resolver problemas cuando
se violan esos criterios. Para ello, se puede usar
JUnitPerf (http://www.clarkware.com/software/JUnitPerf.html)
o cualquier herramienta de automatización
de pruebas de rendimiento.
La
clave de una afinación efectiva es una asignación eficiente
de recursos. Es decir, se debería invertir la mayor parte
del tiempo en afinar las áreas de la aplicación que
producirán el mayor beneficio. Lo contrario también
es cierto: no se debería invertir tiempo intentando optimizar
cada elemento de código que se escribe, excepto si se sabe
que es crítico para el rendimiento. Esto no quiere decir que
se deba escribir código descuidado, sino que debe usarse el
código más simple que funcione, como mínimo
hasta que las pruebas manuales o automáticas de rendimiento
confirmen que es necesario optimizarlo.
|