|
Cuando
se requiere alta disponibilidad y un entorno más escalable,
se puede usar clustering. Es importante elegir una
plataforma que soporte clustering en cada una de las
capas más
importantes. Además, necesita elegir entre clustering horizontal
o vertical. Estas son las opciones con las que cuenta:
-
Con
una única CPU, puede añadir máquinas
virtuales de Java adicionales y hacer balance de
carga entre ellas.
-
Conforme
aumenta la carga, puede añadir CPUs adicionales
y hacer clustering con múltiples máquinas
virtuales de Java usando enrutamiento de conexiones,
tolerancia a fallos y balance de carga.
-
Puede
hacer clustering con múltiples máquinas,
con el servidor de aplicaciones proporcionando tolerancia
a fallos, clustering, balance de carga y enrutamiento
de conexiones.
Considere
el escenario en la figura 6. Este escenario despliega cuatro capas,
con las capas de presentación, negocios y recursos implementando
clustering. Además, se coloca el contenido Web estático
en una caché, lo que ahorra comunicaciones costosas y puede
mejorar dramáticamente el rendimiento. Una ventaja de este
diseño es que no tiene un único punto de fallo, siempre
que la implementación proporcione hardware de red redundante.
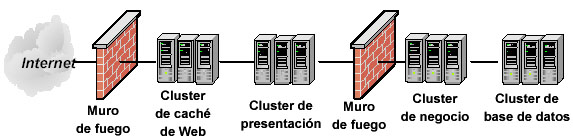
Figura
6. En un despliegue con clustering se obtiene escalabilidad añadiendo
hardware y se aumenta la disponibilidad añadiendo redundancia.
Por
supuesto, conforme el entorno se hace más complejo, también
se aumenta la complejidad de su administración. Conforme se
añaden clusters y capas, se debe trabajar duro para que la
administración del sistema global siga siendo sencilla.
7.2.
Buena práctica número 19. No restrinja sus opciones
de despliegue en tiempo de diseño
Cuando
sea posible, debería mantener la máxima flexibilidad
mientras se construye el sistema. De esta manera, si necesita cambios
en el despliegue, estará preparado para adaptarse a ellos.
Esto requiere prestar una gran atención al diseño de
la aplicación, de lo que nos ocuparemos a continuación.
Gestión
del estado de sesión
Se
puede usar una amplia variedad de técnicas para manejar el
estado de sesión en aplicaciones Java del lado del servidor.
Con independencia de la que use, debería asegurarse de que
soporta estado distribuido de sesión.
-
Se
puede usar la API J2EE de manejo de sesión,
que es la mejor opción si el estado de sesión
es ligero. Tenga presente que esta implementación
no soporta cantidades masivas de datos, así que
debería hacer que la cantidad de datos de
la sesión sea pequeña.
-
Se
puede diseñar una arquitectura que asegure
que todas las comunicaciones de un único cliente
se producen siempre con el mismo servidor. Esta solución
se conoce como el bit pegajoso (“sticky
bit”).
-
Se
pueden usar beans EJB de entidad
o beans de sesión con estado para implementar
una gestión propia de estado distribuido.
Si lo hace así, debe asegurarse de que cuenta
con una estrategia para borrar periódicamente
viejas conversaciones, si ello es necesario.
Cada
una de estas soluciones puede implementarse de forma que mantenga
adecuadamente un estado distribuido de sesión.
Caché
Cualquier
solución de caché que desarrolle para la aplicación
debe soportar también acceso distribuido. Por esta razón,
es mejor usar patrones de diseño y software preexistente para
la mayoría de necesidades de caché. Además,
tenga presente que el clustering puede degradar el rendimiento de
la caché por dos razones:
-
La
invalidación distribuida de datos “sucios” implica
una sobrecarga en las comunicaciones.
-
Con
N cachés diferentes, hay menos probabilidad
de obtener una correspondencia en la caché,
excepto si se implementa una solución “de
bit pegajoso”.
Muros
de fuego
Asegúrese
que entiende donde va a ubicar cada capa de la solución en
relación a los muros de fuego. Cuando sea posible, use soluciones
que no limiten sus opciones de despliegue. Por ejemplo, el cliente
debería comunicarse con el servidor de presentación
estrictamente usando HTTP o HTTPS. Incluso los clientes pesados o
los applets de Java pueden usar estos protocolos si se programa con
un poco de cuidado.
|